- Open a TCP connection: The TCP connection is used to send a request, or several, and receive an answer. The client may open a new connection, reuse an existing connection, or open several TCP connections to the servers.
- Send an HTTP message: HTTP messages (before HTTP/2) are human-readable. With HTTP/2, we cannot read the messages directly, but the principle remains the same. For example:
GET / HTTP/1.1 Host: developer.mozilla.org Accept-Language: fr - Read the response sent by the server. Here is an example.
HTTP/1.1 200 OK Date: Sat, 09 Oct 2010 14:28:02 GMT Server: Apache Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT ETag: "51142bc1-7449-479b075b2891b" Accept-Ranges: bytes Content-Length: 29769 Content-Type: text/html <!DOCTYPE html>… (here come the 29769 bytes of the requested web page) - Close or reuse the connection for further requests.
9 The Application Layer
Chapter Objectives
- Explain the role of client–server architectures at the application layer.
- Analyze an HTTP header, request, and response.
- Summarize the security functions of HTTPS protocol.
- Explain the purpose of the SSH protocol.
- Describe the functions and major features of the Domain Name System (DNS).
- Describe the functions and major features of the Dynamic Host Configuration Protocol (DHCP).
- Summarize the functions of the FTP, IMAP, LDAP, POP, SMTP, and SNMP protocols.
- Explain the elements of the TLS 1.3 protocol, including the TLS handshake, perfect forward secrecy (PFS), and the TLS cipher suite.
Introduction
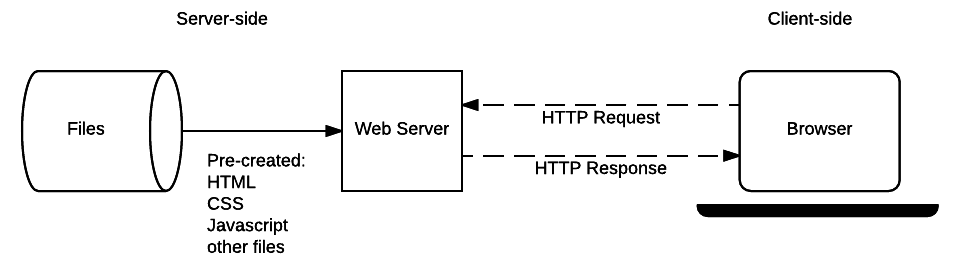
As we learned earlier in this text, in the client-server architecture, a server provides services to clients that exchange information with it.
Client-Server Overview (MDN). https://developer.mozilla.org/en-US/docs/Learn/Server-side/First_steps/Client-Server_overview.
Clients and servers communicate by exchanging two types of messages (as opposed to a stream of data). The messages sent by the client, such as a Web browser, are called requests and the messages sent by the server as an answer are called responses.
Various types of servers and clients are part of this ecosystem. A web server provides information in response to the query sent by its clients. A print server prints documents sent as queries by the client. When queried, an email server forwards email messages to the designated recipient, while a music server delivers the music requested to the client.
Networked applications do not exchange random messages. In order to ensure that the server is able to understand the queries sent by a client, and also that the client is able to understand the responses sent by the server, they must both agree on a set of syntactic and semantic rules. These rules define the format of the messages exchanged as well as their ordering. This set of rules at the application layer make up an application-level protocol.
An application-level protocol is similar to a structured conversation between humans. Assume that Alice wants to know the current time but does not have a watch. If Bob passes close by, the following conversation could take place:
- Alice: Hello
- Bob: Hello
- Alice: What time is it ?
- Bob: 11:55
- Alice: Thank you
- Bob: You’re welcome
Request messages are sent by the client to the server to ask for a service or a resource. Response messages are sent by the server to the client to provide the requested service or resource, or to indicate an error or a status. For example, in the HTTP protocol, the client sends a GET request message to the server to ask for a web page, and the server sends a response message with the web page content or an error code. A complete document is reconstructed from the different sub-documents fetched, for instance, text, layout description, images, videos, scripts, and more.

Source: An Overview of HTTP. https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview.
Most applications exchange strings that are composed of fixed or variable numbers of characters. A common solution to define the character strings that are acceptable is to define a grammar using a Backus-Naur Form (BNF) such as the Augmented BNF defined in RFC 5234. A BNF is a set of production rules that generate all valid character strings, and describes the rules and formats (i.e., the syntax) for exchanging messages between applications on different hosts. BNF can help to ensure that the messages are well-formed and unambiguous, and that they can be parsed and interpreted correctly by the applications. BNF can also help to document and standardize application protocols, making them easier to understand and implement by different parties. BNF is widely used to describe the syntax of many common application protocols. We will cover a few of these in this chapter.
Application Layer Protocols
Some common application layer protocols include HTTP, DNS, DHCP, FTP, SMTP SNMP, IMAP/POP, and FTP. HTTPS, TLS, SSL, and DNSSEC are also related to application layer protocols, enabling encryption and authentication between applications on different hosts.
Hypertext Transfer Protocol (HTTP)
Hypertext Transfer Protocol (HTTP) is a text-based protocol that governs the movement of web traffic and is the foundation of any data exchange on the Web. A typical request has a method and a path, such as GET /index.html , which retrieves the landing page of a website. Responses have a response code, message, and optionally, some data.
Both requests and responses can take advantage of headers, arbitrary lines of text following the initial request or response. Because headers were designed to be open-ended, many new headers have been added over time. A modern web request/response usually has far more information in the headers than just the basics defined in HTTP 1.1.
HTTP messages, as defined in HTTP/1.1 and earlier, are human-readable. In HTTP/2, these messages are embedded into a binary structure, called a frame, allowing optimizations such as the compression of headers and multiplexing. Even if only part of the original HTTP message is sent in this version of HTTP, the semantics of each message is unchanged and the client reconstitutes (virtually) the original HTTP/1.1 request. Therefore, we find it useful to comprehend HTTP/2 messages in the HTTP/1.1 format.
Unencrypted HTTP traffic is sent over port 80 and is vulnerable to attack as all information is sent in cleartext.
When a client wants to communicate with a server, either the final server or an intermediate proxy, it performs the following steps:
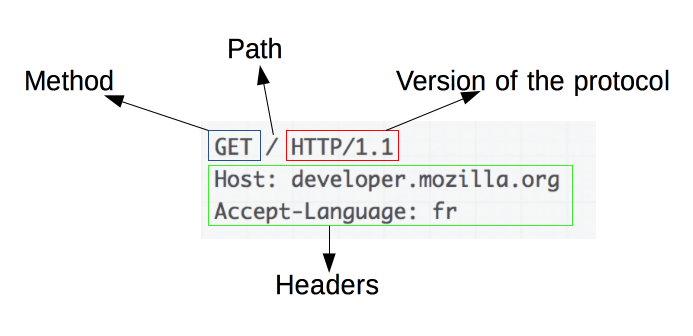
Below is the format of an example HTTP request:
Source: An Overview of HTTP (https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview)
Requests consist of the following elements:
- An HTTP method, usually a verb like GET or POST, or a noun like OPTIONS or HEAD. These defines the operation the client wants to perform. Typically, a client wants to fetch a resource (using GET) or post the value of an HTML form (using POST), though more operations may be needed in other cases.
- The path of the resource to fetch, which is the URL of the resource stripped from elements that are obvious from the context, for example, the domain (developer.mozilla.org), or the TCP port (here, 80).
- The version of the HTTP protocol.
- Optional headers that convey additional information for the servers.
- A body, for some methods like POST, similar to those in responses, which contain the resource.
Responses
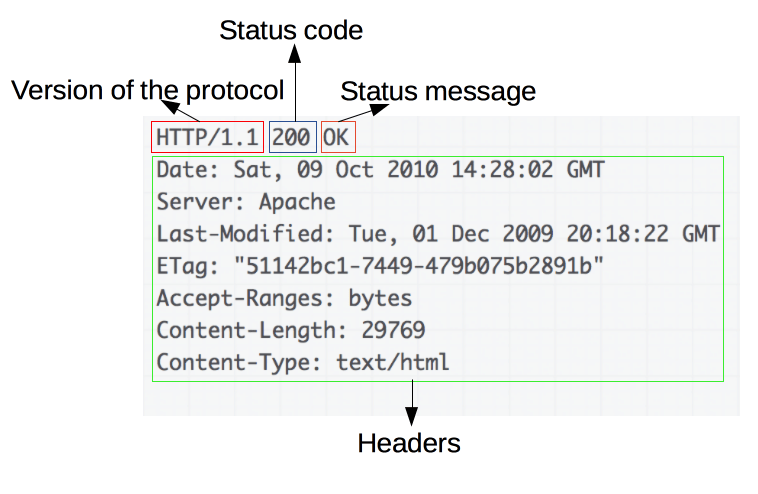
Below is the format of an HTTP response:
An Overview of HTTP (https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview)
Responses consist of the following elements:
- The version of the HTTP protocol they follow.
- A status code, indicating if the request was successful or not, and why.
- A status message, a non-authoritative short description of the status code.
- HTTP headers, similar to those for requests.
- Optionally, a body containing the fetched resource.
Some standard response codes are shown below.
| Code | Message |
|---|---|
|
200 |
OK |
|
202 |
Accepted |
|
400 |
Bad Request |
|
401 |
Unauthorized |
|
403 |
Forbidden |
|
404 |
Not Found |
|
500 |
Internal Server Error |
|
502 |
Bad Gateway |
|
503 |
Service Unavailable |
Hypertext Transfer Protocol Secure (HTTPS)
Hypertext Transfer Protocol Secure (HTTPS) solves the problem of unencrypted traffic by wrapping HTTP requests in TLS, which we will cover at the end of this section. HTTPS traffic uses port 443 and is typically signified in a browser with a lock icon in the upper left-hand corner. By clicking on the icon, users can learn more about the certificates being used for communication. Utilizing a robust PKI (public key infrastructure), HTTPS allows for safe HTTP communication between client and server.
The Domain Name System (DNS)
Assuming the DNS server cannot find the name, it will query a root server for a top level domain (TLD) server, which maintains a listing of authoritative nameservers for that particular domain (edu, com, net, org, gov, etc.). Finally once an authoritative nameserver is found, it will respond with the IP address for that particular hostname, which will be cached and sent back through the user’s primary DNS server to the user.
While RFC 819 discussed the possibility of organizing the names as a directed graph, the Internet opted for a tree structure to contain all names. In this tree, the top-level domains are those that are directly attached to the root. The set of top-level domain-names is managed by the Internet Corporation for Assigned Names and Numbers (ICANN), which holds ongoing discussions to increase the number of top-level domains.
Each top-level domain is managed by an organization that decides how sub-domain names can be registered. Most top-level domain names use a first-come first served (FCFS) system, and allow anyone to register domain names, but there are some exceptions. For example, .gov is reserved for the United States government, and .int is reserved for international organizations.
Watch an overview for the DNS tree structure by Barry Brown (CC-BY).
The syntax of the domain names has been defined more precisely in RFC 1035. This document recommends the following BNF for a fully qualified domain name (the domain names themselves have a much richer syntax).
domain ::= subdomain | ” “
subdomain ::= label | subdomain "." label
label ::= letter [ [ ldh-str ] let-dig ]
ldh-str ::= let-dig-hyp | let-dig-hyp ldh-str
let-dig-hyp ::= let-dig | "-"
let-dig ::= letter | digit
letter ::= any one of the 52 alphabetic characters A through Z in upper case and a through z in lowercase
digit ::= any one of the ten digits 0 through 9
This grammar specifies that a host name is an ordered list of labels separated by the dot (.) character. Each label can contain letters, numbers and the hyphen character (–). Fully qualified domain names are read from left to right. The first label is a hostname or a domain name followed by the hierarchy of domains and ending with the root implicitly at the right. The top-level domain name must be one of the registered TLDs.
The Domain Name System was created at a time when the Internet was mainly used in North America. The initial design assumed that all domain names would be composed of letters and digits RFC 1035. As Internet usage grew in other parts of the world, it became important to support non-ASCII characters. For this, extensions have been proposed to the Domain Name System RFC 3490. In a nutshell, the solution that is used to support Internationalized Domain Names works as follows. First, it is possible to use most of the Unicode characters to encode domain names and hostnames, with a few exceptions (for example, the dot character cannot be part of a name since it is used as a separator). Once a domain name has been encoded as a series of Unicode characters, it is then converted into a string that contains the xn-- prefix and a sequence of ASCII characters. More details on these algorithms can be found in RFC 3490 and RFC 3492.
The possibility of using all Unicode characters to create domain names opened a new form of attack called the homograph attack. This attack occurs when two character strings or domain names are visually similar but do not correspond to the same server. A simple example is https://G00GLE.COM and https://GOOGLE.COM. These two URLs are visually close but they correspond to different names (the first one does not point to a valid server). With other Unicode characters, it is possible to construct domain names that are visually equivalent to existing ones.
DNS Resolution
How do client hosts or applications retrieve the mapping for a given name?
DNS resolution of namespaces is the process of finding the IP address of a host based on its domain name. A domain name is a human-readable name that identifies a host on a network, such as www.example.com. Each nameserver stores part of the distributed database and answers the queries sent by clients. There is at least one nameserver that is responsible for each domain. A sub-domain may contain both host names and sub-domains. A namespace is a collection of domain names that are organized in a hierarchical tree structure, such as the DNS namespace. The DNS namespace consists of different levels of domains, such as top-level domains (TLDs), second-level domains, and subdomains. Each domain has one or more name servers that store information about the hosts in that domain. For example, the name server for the .com TLD stores information about all the second-level domains that end with .com, such as example.com.
To resolve a domain name into an IP address, a client needs to query a DNS server. The DNS server can be either a recursive resolver or an authoritative server. A recursive resolver is a server that acts as an intermediary between the client and the authoritative servers. It follows a chain of referrals from the root nameserver to the TLD server to the authoritative server for the queried domain name, and returns the IP address to the client. An authoritative server is a server that hosts a zone, which is a portion of the DNS namespace. It can answer queries for any name in its zone directly, without contacting other servers.
For example, suppose a client wants to resolve www.yahoo.com into an IP address. The client sends a query to its recursive resolver, which then contacts the root nameserver for the DNS namespace. The root nameserver responds with a referral to the .com TLD server. The recursive resolver then contacts the .com TLD server, which responds with a referral to the example.com authoritative server. The recursive resolver then contacts the example.com authoritative server, which responds with the IP address of www.example.com. The recursive resolver then sends the IP address back to the client, which can then connect to the host.
DNS resolvers have several advantages over letting each Internet host directly query nameservers. Firstly, regular Internet hosts do not need to maintain the up-to-date list of the addresses of the root servers. Secondly, regular Internet hosts do not need to send queries to nameservers all over the Internet. Furthermore, as a DNS resolver serves a large number of hosts, it can cache the received answers. This allows the resolver to quickly return answers for popular DNS queries and reduces the load on all DNS servers [JSBM2002].
See how DNS resolution works, step by step, in this video by Barry Brown (CC-BY).
Benefits of Names
In addition to being more human friendly, using names instead of addresses inside applications has several important benefits. Let’s consider a popular application that provides information stored on servers. The server provides information upon requests from client processes. A first deployment of this application would be to rely only on addresses. In this case, the server process would be installed on one host and the clients would connect to this server to retrieve information. Such a deployment has several drawbacks :
- If the server process moves to another physical server, all clients must be informed about the new server address.
- If there are many concurrent clients, the load of the server will increase without any possibility of adding another server without changing the server addresses used by the clients.
Using names solves these problems. In addition, if the clients are configured with the name of the server, they will query the name service before contacting the server. The name service will resolve the name into the corresponding address. If a server process needs to move from one physical server to another, it suffices to update the name to address mapping on the name service to allow all clients to connect to the new server. The name service also enables the servers to better sustain the load. Assume a very popular server is accessed by millions of users. This service cannot be provided by a single physical server due to performance limitations. Thanks to the utilization of names, it is possible to scale this service by mapping a given name to a set of addresses. When a client queries the name service with the server’s name, the name service returns one of the addresses in the set. Various strategies can be used to select one particular address inside the set of addresses. A first strategy is to select a random address in the set. A second strategy is to maintain information about the load on the servers and return the address of the less loaded server. Note that the list of server addresses does not need to remain fixed. It is possible to add and remove addresses from the list to cope with load fluctuations. Another strategy is to infer the location of the client from the name request and return the address of the closest server.
Mapping a single name onto a set of addresses allows popular servers to dynamically scale. There are also benefits in mapping multiple names, possibly a large number of them, onto a single address. Consider the case of information servers run by individuals or SMEs. Some of these servers attract only a few clients per day. Using a single physical server for each of these services would be a waste of resources. A better approach is to use a single server for a set of services that are all identified by different names. This enables service providers to support a large number of server processes, identified by different names, onto a single physical server. If one of these server processes becomes very popular, it will be possible to map its name onto a set of addresses to be able to sustain the load. This can be done dynamically if needed.
Names provide a lot of flexibility compared to addresses. For the network, they play a similar role as variables in programming languages. No programmer using a high-level programming language would consider using hardcoded values instead of variables. For the same reasons, all networked applications depend on names and abstract the addresses as much as possible.
The official list of top-level domain names is maintained by IANA at http://data.iana.org/TLD/tlds-alpha-by-domain.txt. Until February 2008, the root DNS servers only had IPv4 addresses. IPv6 addresses were slowly added to the root DNS servers to avoid creating problems as discussed in http://www.icann.org/en/committees/security/sac018.pdf. As of February 2021, a few DNS root servers are still not reachable using IPv6. The full list is available at http://www.root-servers.org/.
DNS operates mostly via UDP on port 53. This means that although DNS is designed to be resilient and decentralized but unfortunately, the traffic is not authenticated or encrypted. This has made it a target for MitM attacks. Likewise, cache hits and misses can yield information as to what names have been recently resolved (e,g., as with the Sony Rootkit). The recursive nature of DNS has also allowed for DoS attacks in the past, but much of that has been solved by limiting recursive queries to the user-facing DNS servers (i.e., the one given to you by your DHCP request).
DNSSEC
Domain Name System Security Extensions (DNSSEC) is a suite of extension specifications designed to authenticate responses to domain name lookups. This can help prevent MitM attacks by checking the digital signature of the responding server. While this is certainly helpful, it is important to note that DNSSEC does not provide confidentiality. DNS resolutions can still be monitored by anyone who has access to the traffic.
Dynamic Host Configuration (DHCP)
Dynamic Host Configuration Protocol (DHCP) is used to allow new clients on a network obtain an IP address and information about the services provided. IPv4 addresses can be thought of as being in two groups: static addresses and dynamic addresses. Dynamic addresses are distributed by a DHCP server for a particular lease time. When the time is up, the DHCP server may distribute the address to another client. DHCP servers can also give information about proxies, domain name servers (DNSs), gateways, and more.
The DHCP protocol consists of four basic steps:
- Discover: The host sends a broadcast message to the network, called a DHCPDISCOVER, to find a DHCP server that can offer an IP address.
- Offer: The DHCP server responds to the host with a message, called a DHCPOFFER, that contains an IP address and other parameters, such as subnet mask, default gateway, DNS server, etc.
- Request: The host chooses one of the offers and sends a message, called a DHCPREQUEST, to the DHCP server to request the IP address and parameters.
- Acknowledge: The DHCP server confirms the request and sends a message, called a DHCPACK, to the host with the IP address and parameters. The host then configures its network interface with the IP address and parameters.
The DHCP protocol also allows hosts to renew or release their IP addresses, and DHCP servers to inform hosts of changes in configuration.
After the discover message and the offer message, more than one server could reply with an offer message. The offer messages include IP addresses but also other options like default gateways, leased time, expiration time, etc. The client must make a decision as to which address or which information to take, and reply with a request message to the chosen server. Finally, the selected server will say, “Okay. I acknowledge your request. Here is the information. Now we start a lease time, and you are the owner of the address temporarily.” This is a DHCP acknowledgment message. The client will see the acknowledgement and will start operating.
If you place a router in the middle of the conversation, routers will not forward local broadcasts. So you must configure that router so that requests and replies can travel back and forth across that router. If you are going to configure a router as a DHCP server, then the router must support DHCP and perform all of these calls.
The process of relaying a message from a host to a remote DHCP server is shown

DHCP Address Allocation
Providing an IP address to a client is the most important task performed by a host configuration protocol. Together with that, we receive information for the network segment, default gateway, DNS servers, domain name, TFTP servers (important in the IP telephony) and so on. To provide flexibility for configuring addresses on different types of clients, the DHCP standard includes three different address allocation mechanisms:
- Manual Allocation: Also known as a reservation. A particular IP address is pre-allocated to a single device by an administrator. DHCP only communicates the IP address to the device. The IP address is mapped to the MAC address of the requesting device.
- Automatic Allocation: DHCP automatically assigns an IP address permanently to a device, selecting it from the predefined pool of available addresses.
- Dynamic Allocation: DHCP assigns an IP address from a pool of addresses for a limited period of time chosen by the server, or until the client tells the DHCP server that it no longer needs the address (for example, by executing the command “ipconfig /release” under a Windows OS).
In the case where DHCP dynamically assigns IP addresses to hosts, hosts cannot keep addresses indefinitely, as this would eventually cause the server to exhaust its address pool. At the same time, a host cannot be depended upon to give back its address, since it might have crashed, been unplugged from the network, or been turned off. This is why DHCP allows addresses to be leased for some period of time. Once the lease expires, the server is free to return that address to its pool. A host with a leased address clearly needs to renew the lease periodically if in fact it is still connected to the network and functioning correctly.
DHCP illustrates an important aspect of the scaling of network management. While discussions of scaling often focus on keeping the state in network devices from growing too fast, it is important to pay attention to the growth of network management complexity. By allowing network managers to configure a range of IP addresses per network rather than one IP address per host, DHCP improves the manageability of a network.
Note that DHCP may also introduce some more complexity into network management, since it makes the binding between physical hosts and IP addresses much more dynamic. This may make the network manager’s job more difficult if, for example, it becomes necessary to locate a malfunctioning host.
From a security standpoint, someone impersonating a DHCP server can wreak havoc on a network. These rogue DHCP servers can cause traffic to be redirected to initiate MitM attacks or cause DoS attacks. DHCP relies on broadcast Address Resolution Protocol (ARP) messages and does not make use of authentication, meaning that once an attacker is on the same Ethernet segment as the victim machines, all bets are off.
Remote Desktop Protocol (RDP) is build into Windows and is typically used to control a machine remotely. It works over port 3389 via TCP or UDP. While RDP can be quite useful for performing remote administration on a remote machine, it can also be a large security hole if a bad actor gains access. RDP use in ransomware attacks is on the rise as ransomware programs may use RDP to find other machines to attack.
Telnet
Telnet is an antiquated remote administration tool that gives access to a shell via a cleartext channel. Telnet runs on port 23 and while still occasionally in use, it should largely be phased out. You will still find telnet in embedded applications and legacy systems. You may also see the client being used to inspect other types of traffic. For example, you can use a telnet client to submit HTTP requests or send email via SMTP.
LDAP

Lightweight Directory Access Protocol (LDAP) is used for accessing and maintaining directory information services. It’s primary use is with Windows Active Directory (AD), where it can be used to obtain information regarding users and resources from an AD server. Clients can authenticate through the server and obtain privileges to read or read/write certain entries. LDAP did not originally support encryption, until LDAP over SSL (LDAPS) was developed. LDAP uses TCP and UPD over port 389 and LDAPS uses TCP over port 636.
IMAP/POP3
Internet Message Access Protocol (IMAP) and Post Office Protocol 3 (POP3) are two protocols used to retrieve email from a server. IMAP is the more recent protocol, and supports saving mail on the server and folders. POP3 is more primitive, supporting only the retrieval (and subsequent deletion from the server) of emails. Both protocols use cleartext and are now commonly run over TLS. POP3 defaults to TCP port 110 or 995 if using TLS. IMAP defaults to TCP port 143 or 993 if using TLS. In the age of webmail, it is easy to forget about these protocols, but a security specialist must keep them in mind as they may still be used in support of corporate devices.
SMTP
Simple Mail Transfer Protocol (SMTP) is used for sending/forwarding email. As it states, it is a simple protocol consisting of lines of text. Basic SMTP used TCP on port 25. SMTP was later expanded to support authentication and finally wrapped in TLS still using TCP on port 587. SMTP servers accept outgoing mail from (hopefully) authenticated clients, route mail to other SMTP servers based on the Mail Exchange (MX) information in DNS records, and accept mail for their domain from other SMTP servers. Various checks have been implemented in SMTP servers to ensure that messages from domains actually come from those domains. This is largely used to combat spam, which continues to be a problem.
NTP
Network Time Protocol (NTP) uses UDP over port 123 to sync the system time with a time server. NTP servers are layered in stratums, with the lowest stratums being closest to the most accurate sources of time, atomic clocks, GPS, etc. NTP is important as many protocols, including several key exchanges, require system clocks to be in sync. System clocks are also used to check when certificates expire and used in logs to indicate when something happened. Without an accurate, synchronized system clock, many things will fail in surprising ways.
FTP
File Transfer Protocol is a relatively simple, text-based protocol for sending files between machines. FTP uses TCP on port 21 and traditionally establishes two channels: one for protocol messages, and one binary channel for data. The interesting thing about this setup is that the FTP server would initiate the connection of the data channel from server to client, meaning that in many NAT situations where the client couldn’t be easily reached behind a firewall, it would fail. The solution to this problem was passive FTP, which uses one channel established by the client.
Despite this initial shortcoming, FTP has proven to be incredibly popular and is still used in many corporate environments. You may see FTP being used to transmit bulk data for import to systems or used to update firmware in embedded systems. You can use FTP with a commandline ftp client, a graphical client such as Filezilla or SecureFX, or even in most web browsers with the ftp:// URL scheme.
Unfortunately, FTP does not support authentication systems other than passwords and the passwords are sent in plaintext. As such Secure FTP (SFTP) is recommended. SFTP uses an SSH connection to send and receive files over an encrypted channel. SFTP also supports all SSH authentication methods.
SNMP
Simple Network Management Protocol (SNMP) is used for gathering information about the workings of a network. It is broken into two groups: clients using UDP port 161 (TLS 10161) and a manager using UDP port 162 (TLS 10162). The manager collects messages from the clients regarding the operations of the network and uses this information to take actions as necessary. SNMP can be used to pass information about the temperature of a machine, how many current connections, real-time channel capacity utilization, etc. SNMP is currently up to version 3, which is encrypted and requires authentication. This is particularly important because SNMP is a very powerful protocol that could exchange potentially valuable information to an attacker. Access to SNMP should be limited and its usage on a network should be monitored.
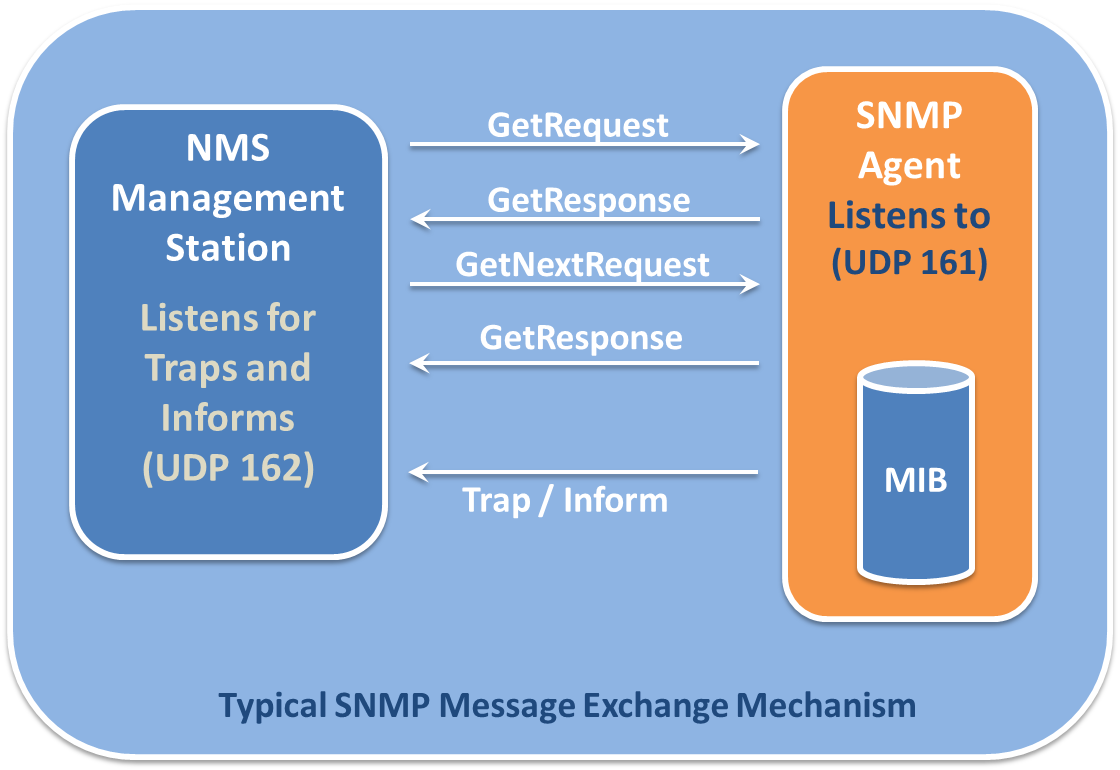
SNMP by Deegii121314 used under CC-BY-SA 4.0
SSH
Secure Shell (SSH) is the most widely deployed remote administration tool. SSH provides access to a shell via an encrypted connection. SSH supports many options including SOCKS5 proxies, port forwarding, and the usage of multiple authentication schemes: password, key, hardware device, etc. SSH uses TCP on port 22.
TLS (SSL)

The Transport Layer Security (TLS) family of protocols were initially proposed under the name Secure Socket Layer (SSL). The first deployments used this name and many researchers still refer to this security protocol as SSL [FKC1996]. In this chapter, we use the official name that was standardized by the IETF: TLS for Transport Layer Security. TLS allows cleartext protocols used on the web to be encrypted. It is a general purpose protocol, designed as a layer through which other protocols communicate. The TLS protocol was designed to be usable by a wide range of applications that use the transport layer to reliably exchange information.
TLS is mainly used over the TCP protocol. TLS is responsible for the encryption and the authentication of the SDUs exchanged by the application layer protocol, while TCP provides the reliable delivery of this encrypted and authenticated bytestream. TLS is used by many different application layer protocols. The most frequent ones are HTTP (HTTP over TLS is called HTTPS), SMTP RFC 3207 or POP and IMAP RFC 2595, but proprietary application-layer protocols also use TLS [AM2019]. There are also variants of TLS that operate over SCTP RFC 3436 or UDP RFC 6347, but these are outside the scope of this chapter.
TLS 1.3 is the most current version, but not all websites support it. TLS 1.2 is still considered safe if best practices are followed and TLS 1.1 or lower is considered depreciated.
A TLS session can be initiated in two different ways. First, the application can use a dedicated TCP port number for application layer protocol x-over-TLS. This is the solution used by many HTTP servers that reserve port 443 for HTTP over TLS. This solution works, but it requires reserving two ports for each application: one where the application-layer protocol is used directly over TCP and another one where the application-layer protocol is used over TLS. Given the limited number of TCP ports that are available, this is not a scalable solution. The table below provides some of the reserved port numbers for application layer protocols on top of TLS.
| Application | TCP port | TLS port |
|---|---|---|
| POP3 | 110 | 995 |
| IMAP | 143 | 993 |
| NNTP | 119 | 563 |
| HTTP | 80 | 443 |
| FTP | 21 | 990 |
A second approach to initiate a TLS session is to use the standard TCP port number for the application layer protocol and define a special message in this protocol to trigger the start of the TLS session. This is the solution used for SMTP with the STARTTLS message. This extension to SMTP RFC 3207 defines the new STARTTLS command. The client can issue this command to indicate to the server that it wants to start a TLS session as shown in the example below captured during a session on port 25.
220 server.example.org ESMTP
EHLO client.example.net
250-server.example.org
250-PIPELINING
250-SIZE 250000000
250-ETRN
250-STARTTLS
250-ENHANCEDSTATUSCODES
250-8BITMIME
250 DSN
STARTTLS
220 2.0.0 Ready to start TLS
For the remainder of this chapter, we assume that the TLS session starts immediately after the establishment of the TCP connection. This corresponds to the deployments on web servers. We focus our presentation of TLS on this very popular use case. TLS is a complex protocol that supports other features than the one used by web servers. A more detailed presentation of TLS may be found in [KPS2002] and [Ristic2015].
A TLS session is divided in two phases: the handshake and the data transfer. During the handshake, the client and the server negotiate the security parameters and the keys that will be used to secure the data transfer. During the second phase, all the messages exchanged are encrypted and authenticated with the negotiated algorithms and keys.
The TLS Handshake
TLS uses a handshake process to establish a secure session between the server and the browser. During a session, the server and client exchange messages that contain information such as the supported TLS versions, cipher suites, random numbers, certificates, and keys. The basic process is outlined below.
- The browser starts the handshake by sending a message to the server with its preferences and a random number. This random number is called a nonce, which means it is only used once in this communication. A nonce helps to prevent replay attacks, where an attacker could reuse old messages to impersonate the browser or the server.
- The server replies with its choices and another random number. The server also sends its certificate, which proves its identity and contains its public key.
- The browser checks the validity of the server’s certificate and generates a secret key, which it encrypts with the server’s public key. The browser also sends a message that verifies the integrity of the previous messages. The server decrypts the secret key with its private key, and both parties use it to create more keys for encryption and authentication.
- The browser and the server exchange messages to confirm that they have the same keys, and that they are ready to encrypt their communication. This is called the Finished message.
- The browser and the server can now exchange application data, such as HTTP requests and responses, using symmetric encryption and authentication with the keys they have generated.
The TLS four-way handshake is illustrated in the figure below.

https://en.m.wikipedia.org/wiki/File:Full_TLS_1.2_Handshake.svg
Perfect Forward Secrecy
Perfect Forward Secrecy (PFS) is an important property for key exchange protocols. A protocol provides PFS if its design guarantees that the keys used for former sessions will not be compromised even if the private key of the server is compromised. Recent implementations of TLS prefer ECDHE_RSA or ECDHE_ECDSA encryption when Perfect Forward Secrecy is required.
Two important messages will be sent by the client and the server to conclude the handshake and start the data transfer phase.
The client sends the ChangeCipherSpec message followed by the Finished message. The ChangeCipherSpec message indicates that the client has received all the information required to generate the security keys for this TLS session. This message can also appear later in the session to indicate a change in the encryption algorithms that are used. The Finished message is more important. It confirms to the server that the TLS handshake has been performed correctly and that no attacker has been able to modify the data sent by the client or the server. This is the first message that is encrypted with the selected security keys. It contains a hash of all the messages that were exchanged during the handshake.
The server also sends a ChangeCipherSpec message followed by a Finished message.
TLS Cipher Suites
A TLS cipher suite is usually represented as an ASCII string that starts with TLS and contains the acronym of the key exchange algorithm, the encryption scheme with the key size and its mode of operation and the authentication algorithm. For example, TLS_DHE_RSA_WITH_AES_128_GCM_SHA256 is a TLS cipher suite that uses the DHE_RSA key exchange algorithm with 128 bits AES in GCM mode for encryption and SHA-256 for authentication. The official list of TLS cipher suites is maintained by IANA. The NULL acronym indicates that no algorithm has been specified. For example, TLS_ECDH_RSA_WITH_NULL_SHA is a cipher suite that does not use any encryption but still uses the ECDH_RSA key exchange and SHA for authentication.
The TLS Record
After the handshake is completed, the client and the server will exchange authenticated and encrypted records. TLS defines different formats for the records depending on the cryptographic algorithms that have been negotiated for the session. A detailed discussion of these different types of records is outside the scope of this introduction. For illustration, we briefly describe one record format.
As other security protocols, TLS uses different keys to encrypt and authenticate records. These keys are derived from the MasterSecret that is either randomly generated by the client after the RSA key exchange or derived from the Diffie Hellman parameters after the DH_RSA key exchange. The exact algorithm used to derive the keys is defined in RFC 5246.
A TLS record is composed of four different fields :
- Type: The most frequent type is application data which corresponds to a record containing encrypted data. The other types are handshake, change_cipher_spec and alert.
- Protocol Version: This version is composed of two sub fields : a major and a minor version number.
- Length: A TLS record cannot be longer than 16,384 bytes.
- TLSPlainText: This contains the encrypted data
TLS supports several methods to encrypt records. The selected method depends on the cryptographic algorithms that have been negotiated for the TLS session. A detailed presentation of the different methods that can be used to produce the TLSPlainText from the user data is outside the scope of this text.
Improving TLS
In 2014, the IETF TLS working group began to develop version 1.3 of the TLS protocol. Their main objectives [Rescorla2015] for this new version were as follows.
- Simplify the design by removing unused or unsafe protocol features.
- Improve the security of TLS by leveraging the lessons learned from TLS 1.2 and documented attacks.
- Improve the privacy of the protocol.
- Reduce the latency of TLS.
Since 2014, latency has become an important concern for the performance of web services. With TLS 1.2, the download of a web page requires a minimum of four round-trip-times, one to create the underlying TCP connection, one to exchange the ClientHello/ServerHello, one to exchange the keys and then one to send the HTTP GET and retrieve the response. This can be very long when the server is not near the client. TLS 1.3 aimed at reducing this handshake to one round-trip-time and even zero by placing some of the cryptographic handshake in the TCP handshake.
To simplify both the design and the implementations, TLS 1.3 uses only a small number of cipher suites. Five of them are specified in RFC 8446 and TLS_AES_128_GCM_SHA256 must be supported by all implementations. To ensure privacy, all cipher suites that did not provide Perfect Forward Secrecy have been removed. Compression has also been removed from TLS since several attacks on TLS 1.2 exploited its compression capability RFC 7457.
By supporting only cipher suites that provide Perfect Forward Secrecy in TLS 1.3, the IETF aims at protecting the privacy of users against a wide range of attacks. However, this choice has resulted in intense debates in some enterprises. Notably in financial organizations, who have deployed TLS, but wish to be able to decrypt TLS traffic for various security-related activities. These enterprises tried to lobby within the IETF to maintain RSA-based cipher suites that do not provide Perfect Forward Secrecy. Their arguments did not convince the IETF. Eventually, these enterprises moved to ETSI, another standardization body, and convinced the IETF to adopt entreprise TLS, a variant of TLS 1.3 that does not provide Perfect Forward Secrecy [eTLS2018].
There are many more differences between TLS 1.2 and TLS 1.3. Additional details may be found in their respective specifications, RFC 5246 and RFC 8446.
The sections above are adapted from Computer Systems Security: Planning for Success by Ryan Tolboom is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License, except where otherwise noted.
definition
An architecture for computing that enables the separation of functions between front-end data entry and display (client) and back-end request processing (server) in order to bolster the productivity and efficiency of each. This form of distributed computing aims to spread the workload between two devices connected via a network. A smartphone or computer web browser communicating with a Google web server to return results for a query requesting "what is client-server computing" is an example of the client-server architecture in action.
Sulyman, Shakirat. (2014). Client-Server Model. IOSR Journal of Computer Engineering. 16. 57-71. 10.9790/0661-16195771.
Refers to information that is not encrypted, and is not expected to be encrypted. An important distinction between cleartext and plaintext is that cleartext is not encrypted at any stage. This is why HTTP traffic sent over port 80 is considered vulnerable.
“What is Cleartext? | Security Encyclopedia.” [Online]. Available: https://www.hypr.com/security-encyclopedia/cleartext. Accessed: Oct. 10, 2023.
The server’s way of responding to the client. The code response is a three-digit integer. The first integer defines the type of response, and the last two are the role of the response. Examples of first value codes are 1xx informational, 2xx success, 3xx redirection, 4xx client error, and 5xx server error.
“A Complete Guide and List of HTTP Status Codes.” Kinsta®, 24 Feb. 2020, https://kinsta.com/blog/http-status-codes/. Accessed 9 Oct. 2023.
Converts domain names into IP addresses, which allow browsers to get to websites and other Internet resources. Every device on the internet has an IP address, which other devices can use to locate the device. Instead of memorizing a long list of IP addresses, people can simply enter the name of the website, and the DNS gets the IP address for them.
“What is domain name system (DNS)?,” Fortinet, https://www.fortinet.com/resources/cyberglossary/what-is-dns. Accessed Oct. 2, 2023.
An attack leveraged by mistyping or mistakenly entering a domain name that looks the same, but is missing a letter or some other mistake. This attacks occurs when an error in the domain name arrives to a different than expected website, that might contain malicious intentions, leveraging a domain name look-a-like. Umawing, Jovi. “Out of Character: Homograph Attacks Explained | Malwarebytes Labs.” Malwarebytes, 6 Oct. 2017, www.malwarebytes.com/blog/news/2017/10/out-of-character-homograph-attacks-explained. Accessed 10 Oct. 2023.
With a load fluctuation, the load refers to the amount of traffic or activity received by a server. Fluctuations in the amount of data flowing into and out of a server can cause service issues. Often, the term load balancing will be used to address load fluctuation issues, which consists of adding additional servers to a domain.
Tadić, Bosiljka. “Cyclical Trends of Network Load Fluctuations in Traffic Jamming.” Dynamics, vol. 2, no. 4, Dec. 2022, pp. 449–61. DOI.org (Crossref), https://doi.org/10.3390/dynamics2040026.
A protocol on the application level that allows for the modification and access to emails on a server. IMAP allows for access to the email without download, keeping the email on the server, and preventing potentially compromising downloads.
Glossary — Computer Networking : Principles, Protocols and Practice. https://beta.computer-networking.info/syllabus/default/glossary.html. Accessed 10 Oct. 2023
A group of protocols that provide authentication and encryption for communication between a client and web server. TLS is commonly implemented on the server side to conduct the authentication. Most ecommerce websites use TLS to help protect financial or transactional information that is sent between the client and server.
Regenscheid, Andrew, and Geoff Beier. Security Best Practices for the Electronic Transmission of Election Materials for UOCAVA Voters. NIST Internal or Interagency Report (NISTIR) 7711, National Institute of Standards and Technology, 15 Sept. 2011. csrc.nist.gov, https://doi.org/10.6028/NIST.IR.7711. Accessed 16 Oct 2023.

{kind=link}