Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
5. The Data Link Layer
Chapter Objectives
5-1 Describe the fields of a data link frame and their functions.
5-2 Explain the most common transmission errors and how to recover from them.
5-3 Outline techniques that facilitate the reliable transfer of data over the data link layer.
5-4 Describe the format and function of a media access control (MAC) address.
5-5 Outline the primary protocols associated with the data link layer: Async, SDLC, PPP, and ARP.
The Framing Problem
In the prior chapter, we learned about the first layer of the OSI model, the physical layer. In this chapter, we will move on to the the data link layer, the second layer of the OSI model. The data link layer facilitates communication between hosts (network devices) by managing the transmission of data frames over a shared physical medium, between directly connected devices within the same local network segment.
The key functions of the data layer include framing, addressing, and error detection/correction. We’ll discuss framing in this section.
We are typically not interested in exchanging bits between two hosts. Rather, we prefer to write software that deals with larger blocks of data in order to transmit messages or complete files. Thanks to the physical layer service, it is possible to send a continuous stream of bits between two hosts. This stream of bits can include logical blocks of data, but we need to be able to extract each block of data from the bit stream. You may recall from the Overview of Network Models chapter that the unit of information exchanged between two entities in the data link layer is a frame, which can be defined as a sequence of bits that has a particular syntax or structure.
To enable the transmission/reception of frames, the first problem to be solved is how to encode a frame as a sequence of bits, so that the receiver can easily recover the received frame despite the limitations of the physical layer.
If the physical layer were perfect, the problem would be very simple. We would simply need to define how to encode each frame as a sequence of consecutive bits. The receiver would then easily be able to extract the frames from the received bits. Unfortunately, the imperfections of the physical layer make this framing problem slightly more complex because the physical layer is susceptible to interference. This interference in turn can lead to data loss or corruption. To address these issues, the data link layer applies techniques such as framing and encapsulation. Let’s explore how these mechanisms work to ensure reliable data transmission.
The framing problem can be defined as: “How does a sender encode frames so that the receiver can efficiently extract them from the stream of bits that it receives from the physical layer”.
One solution to this problem could be to require the physical layer to remain idle for some time after the transmission of each frame. These idle periods can be detected by the receiver and serve as a marker to delineate frame boundaries. Unfortunately, this solution is not acceptable for two reasons. First, some physical layers cannot remain idle and always need to transmit bits. Second, inserting an idle period between frames decreases the maximum bit rate that can be achieved. Therefore, we need to find other ways to separate frames. This video describes the Ethernet data frame format (Ace Networker, Ethernet Frame Format Explanation, 2018) [6:42].
Concepts Corner
Addressing on the data link layer is done via the MAC address. Each network device is assigned a unique MAC address by its manufacturer. Let’s learn more here!
What is a MAC address?
The local physical address assigned to a network interface controller (NIC) for local communication is the media access control (MAC) address. This communication occurs between multiple devices on a network. In computer networking, different types of addresses are present, and each has its own role.
Why are MAC addresses used?
MAC addresses are unique six-byte long hardware-encoded identifiers also known as EUI (Extended Unique Identifier). MAC addresses identify senders uniquely and receivers on a network or over a communication channel.
How is a MAC Address related to the Data Link Layer?
According to IEEE 802 Standards, the data link layer is divided into two sublayers. The first sublayer is the logical link control (LLC), and the second is the media access control (MAC). On the second sublayer, MAC addresses are used by the data link layer to establish a communication channel.
An Anatomy of a MAC Address
MAC addresses are unique and used worldwide. Millions of online devices communicate through them. We use a 48-bit MAC address (grouped into six bytes) in hexadecimal for the unique identification of devices. Hexadecimal is a number system with base 16 and includes any of the following digits: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, and F. Here is an example of a MAC address format: 01-23-45-67-89-AB.
The first three bytes are used by vendors, and the remaining are used as a serial number of that vendor’s interface card.
Below are the types of MAC addresses:
Unicast: represents a specific device in the network.
Multicast: represents a group of devices in the network.
Broadcast: represents all devices in a network.
How to find a MAC address?
Below are some commands to check your device’s or network card’s MAC address:
// For Windows users CommandforWindowsOS: ipconfig /all
// For Linux users CommandforLinux/UNIXOS: ifconfig -a // -a means all ip link list ip address show
// For Apple usersCommand for MacOS: ifconfig en1 | grep ether
networksetup -listallhardwareports
In the data link layer, bit rate and bandwidth are key metrics that describe how data is transmitted. Bit rate refers to the number of bits sent or received per second, while bandwidth represents the maximum capacity of radio frequencies in a communication channel, measured in hertz (Hz). For example, the human ear is able to decode sounds in roughly the 0-20 KHz frequency range and a Gigabit Ethernet link is theoretically capable of transporting one billion bits per second. Together, the bit rate and bandwidth of a service determine the efficiency and speed of data transfer across a network.
To organize this data for transmission, framing divides the data into manageable units called frames. Frames can be either fixed-size or variable-size. In fixed-size framing, each frame has a predetermined length, eliminating the need for additional markers to indicate where a frame begins or ends. In contrast, variable-size framing requires delimiters, such as special bit patterns or length fields, to distinguish between frames.
Techniques like bit stuffing and character stuffing are used to ensure that these delimiters are not confused with actual data. To enable a receiver to easily delineate the frame boundaries, these two techniques reserve special bit strings as frame boundary markers and encode the frames so that these special bit strings do not appear inside the frames.
Bit stuffing reserves the 01111110 bit string as the frame boundary marker and ensures that there will never be six consecutive “1″ symbols transmitted by the physical layer inside a frame. With bit stuffing, a frame is sent as follows.
First, the sender transmits the marker, i.e., 01111110. Then, it sends all the bits of the frame and inserts an additional bit set to 0 after each sequence of five consecutive 1 bits. This ensures that the sent frame never contains a sequence of six consecutive bits set to 1. As a consequence, the marker pattern cannot appear inside the frame sent. The marker is also sent to mark the end of the frame. The receiver performs the opposite to decode a received frame. It first detects the beginning of the frame, thanks to the 01111110 marker. Then, it processes the received bits and counts the number of consecutive bits set to 1. If a 0 follows five consecutive bits set to 1, this bit is removed since it was inserted by the sender. If a 1 follows five consecutive bits sets to 1, it indicates a marker if it is followed by a bit set to 0. The table below illustrates the application of bit stuffing to some frames.
Original Frame
Transmitted Frame
0001001001001001001000011
01111110000100100100100100100001101111110
0110111111111111111110010
01111110011011111011111011111011001001111110
0111110
011111100111110001111110
01111110
0111111001111101001111110
Table 3-1: An example of bit stuffing
For example, consider the transmission of 0110111111111111111110010. The sender will first send the 01111110 marker followed by 011011111. After these five consecutive bits set to 1, it inserts a bit set to 0 followed by 11111. A new 0 is inserted, followed by 11111. A new 0 is inserted followed by the end of the frame 110010 and the 01111110 marker.
Bit stuffing inserts extra bits into a data stream to transmit each frame. The worst case for bit stuffing is of course a long sequence of bits set to 1 inside the frame. If transmission errors occur, stuffed bits or markers can be in error. In these cases, the frame affected by the error and possibly the next frame will not be correctly decoded by the receiver, but it will be able to resynchronize itself at the next valid marker.
Bit stuffing is more straightforward to implement in hardware due to the ease of performing bit-level operations. Hardware can efficiently detect and insert bits, such as adding a 0 after five consecutive 1s, without significant computational overhead.
Implementing bit stuffing in software is more complex because software typically processes data in characters rather than individual bits. As a result, software-based data link layers often use character stuffing, also known as byte stuffing, which operates on frames containing an integer number of characters, usually encoded by relying on the ASCII table, which defines the binary representation of alphanumeric and control characters. Byte stuffing is more commonly employed in modern protocols, especially those that operate at higher layers of the network stack.
RFC 20 provides the ASCII table that is used by many protocols on the Internet. For example, the table defines the following binary representations:
A : 1000011 b
0 : 0110000 b
z : 1111010 b
@ : 1000000 b
space : 0100000 b
In addition, the ASCII table also defines several non-printable or control characters. These characters were designed to allow an application to control a printer or a terminal. These control characters include CR and LF, which are used to terminate a line, and the BEL character, which causes the terminal to emit a sound.
NUL: 0000000 b
BEL: 0000111 b
CR : 0001101 b
LF : 0001010 b
DLE: 0010000 b
STX: 0000010 b
ETX: 0000011 b
Some characters are used as markers to delineate the frame boundaries. Many character stuffing techniques use the DLE, STX and ETX characters of the ASCII character set. DLE STX (or DLE ETX) is used to mark the beginning (end) of a frame. When transmitting a frame, the sender adds a DLE character after each transmitted DLE character. This ensures that none of the markers can appear inside the transmitted frame. The receiver detects the frame boundaries and removes the second DLE when it receives two consecutive DLE characters. For example, to transmit frame 1 2 3 DLE STX 4, a sender will first send DLE STX as a marker, followed by 1 2 3 DLE. Then, the sender transmits an additional DLE character followed by STX 4 and the DLE ETX marker.
Original frame
Transmitted frame
1234
DLE STX 1234 DLE ETX
123DLESTX4
DLE STX 123DLE DLE STX4 DLE ETX
DLE STX DLE ETX
DLE STX DLE DLE STXDLE DLE ETX DLE ETX
Table 3-2: An example of character stuffing
Character stuffing, like bit stuffing, increases the length of the transmitted frames. For character stuffing, the worst frame is a frame containing many DLE characters. When transmission errors occur, the receiver may incorrectly decode one or two frames (e.g. if the errors occur in the markers). However, it will be able to resynchronize itself with the next correctly received markers.
Bit stuffing and character stuffing allow recovering frames from a stream of bits or bytes. This framing mechanism provides a richer service than the physical layer. Through the framing service, one can send and receive complete frames. This video explains character, it byte, stuffing (Tinnel, 2023) [5:02].
Recovering from Transmission Errors
In this section, we develop a reliable data link protocol running above the physical layer service. To design this protocol, we first assume that the physical layer provides a perfect service. We will then develop solutions to recover from the transmission errors.
The data link layer is designed to send and receive frames on behalf of a user. We model these interactions by using the data.request and data.indication primitives. However, to simplify the presentation and to avoid confusion between a data.request primitive issued by the user of the datalink layer entity, and a data.request issued by the data link layer entity itself, we will use the following terminology:
The interactions between the user and the data link layer entity are represented by using the classical data.request and the data.indication primitives
The interactions between the data link layer entity and the framing sub-layer are represented by using send instead of data.request and received (recvd) instead of data.indication
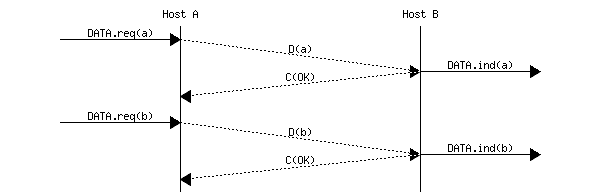
When running on top of a perfect framing sub-layer, a data link entity can simply issue a send(SDU) upon arrival of a data.request(SDU). Similarly, the receiver issues a data.indication(SDU) upon receipt of a recvd(SDU). Such a simple protocol is sufficient when a single SDU is sent. This is illustrated in the figure below.
Figure 3-2: A simple transmission of one SDU at the data link layer
Unfortunately, this is not always sufficient to ensure a reliable delivery of the SDUs. Consider the case where a client sends tens of SDUs to a server. If the server is faster than the client, it will be able to receive and process all the frames sent by the client and deliver their content to its user. However, if the server is slower than the client, problems may arise. The data link entity contains buffers to store SDUs that have been received as a data.request but have not yet been sent. If the application is faster than the physical link, the buffer may become full. At this point, the operating system suspends the application to let the data link entity empty its transmission queue. The data link entity also uses a buffer to store the received frames that have not yet been processed by the application. If the application is slow to process the data, this buffer may overflow and the data link entity will not able to accept any additional frame. The buffers of the data link entity have a limited size and if they overflow, the arriving frames will be discarded, even if they are correct.
To solve this problem, a reliable protocol must include a feedback mechanism that allows the receiver to inform the sender that it has processed a frame and that another one can be sent. This feedback is required even though there are no transmission errors. To include such a feedback, our reliable protocol must process two types of frames:
data frames carrying a SDU
control frames carrying an acknowledgment indicating that the previous frames was correctly processed
These two types of frames can be distinguished by dividing the frame in two parts:
the header that contains one bit set to 0 in data frames and set to 1 in control frames
the payload that contains the SDU supplied by the application
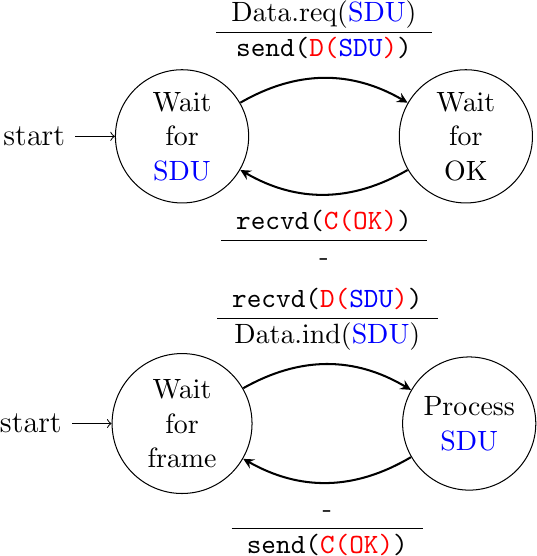
The data link entity can then be modeled as a finite state machine, containing two states for the receiver and two states for the sender. The figure below provides a graphical representation of this state machine with the sender above and the receiver below.
Figure 3-3: A finite state machine illustrating the simplest reliable protocol (sender above, receiver below)
The above FSM shows that the sender has to wait for an acknowledgment from the receiver before being able to transmit the next SDU. The figure below illustrates the exchange of a few frames between two hosts.
Figure 3-4: A sample exchange of a few frames between two hosts.
Reliable Data Transfer
The data link layer must deal with transmission errors. In practice, we mainly have to deal with two types of errors in the data link layer :
Frames can be corrupted by transmission errors
Frames can be lost or unexpected frames can appear
A first glance, losing frames might seem strange on a single link. However, if we take framing into account, transmission errors can affect the frame delineation mechanism and make the frame unreadable. For the same reason, a receiver could receive two (likely invalid) frames after a sender has transmitted a single frame.
To deal with these types of imperfections, reliable protocols rely on different types of mechanisms. Data transmission on a physical link can be affected by the following errors :
random isolated errors where the value of a single bit has been modified due to a transmission error
random burst errors where the values of N consecutive bits have been changed due to transmission errors
random bit creations and random bit removals where bits have been added or removed due to transmission errors
The only solution to protect against transmission errors is to add redundancy to the frames that are sent. Information theory defines two mechanisms that can be used to transmit information over a transmission channel affected by random errors. These two mechanisms add redundancy to the transmitted information, to allow the receiver to detect or sometimes even correct transmission errors. A detailed discussion of these mechanisms is outside the scope of this chapter, but it is useful to consider a simple mechanism to understand its operation and its limitations.
Coding Schemes
Information theory defines coding schemes. There are different types of coding schemes. We will focus on coding schemes that operate on binary strings. A coding scheme is a function that maps information encoded as a string of M bits into a string of N bits. The simplest coding scheme is the (even) parity coding. This coding scheme takes an M bits source string and produces an M+1 bits coded string where the first M bits of the coded string are the bits of the source string and the last bit of the coded string is chosen such that the coded string will always contain an even number of bits set to 1. For example :
1001 is encoded as 10010
1101 is encoded as 11011
This parity scheme has been used in some RAMs as well as to encode characters sent over a serial line. It is easy to show that this coding scheme allows the receiver to detect a single transmission error, but it cannot correct it. However, if two or more bits are in error, the receiver may not always be able to detect the error.
Some coding schemes allow the receiver to correct some transmission errors. For example, consider the coding scheme that encodes each source bit as follows :
1 is encoded as 111
0 is encoded as 000
For example, consider a sender that sends 111. If there is one bit in error, the receiver could receive 011 or 101 or 110. In these three cases, the receiver will decode the received bit pattern as a 1 since it contains a majority of bits set to 1. If there are two bits in error, the receiver will not be able anymore to recover from the transmission error.
This simple coding scheme forces the sender to transmit three bits for each source bit. However, it allows the receiver to correct single bit errors. More advanced coding systems that allow recovering from errors are used in several types of physical layers.
Checksums
The simplest error detection scheme is the checksum. A checksum is basically an arithmetic sum of all the bytes of which a frame is composed. There are different types of checksums. For example, an eight-bit checksum can be computed as the arithmetic sum of all the bytes of (both the header and trailer) of the frame. The checksum is computed by the sender before sending the frame and the receiver verifies the checksum upon frame reception. The receiver discards frames received with an invalid checksum. Checksums can be easily implemented in software, but their error detection capabilities are limited. Cyclical redundancy checks (CRC) have better error detection capabilities [SGP98], but require more CPU when implemented in software.
Error Detection Codes
In addition to framing, data link layers also include mechanisms to detect and sometimes even recover from transmission errors. To allow a receiver to notice transmission errors, a sender must add some redundant information as an error detection code to the frame sent. This error detection code is computed by the sender on the frame that it transmits. When the receiver receives a frame with an error detection code, it recomputes it and verifies whether the received error detection code matches the computed error detection code. If they match, the frame is considered to be valid. Many error detection schemes exist and entire books have been written on the subject. A detailed discussion of these techniques is outside the scope of this book, and we will only discuss some examples to illustrate the key principles.
To understand error detection codes, let us consider two devices that exchange bit strings containing N bits. To allow the receiver to detect a transmission error, the sender converts each string of N bits into a string of N+r bits. Usually, the r redundant bits are added at the beginning or the end of the transmitted bit string, but some techniques interleave redundant bits with the original bits. An error detection code can be defined as a function that computes the r redundant bits corresponding to each string of N bits. The simplest error detection code is the parity bit. There are two types of parity schemes: even parity and odd parity. With the even (or odd) parity scheme, the redundant bit is chosen so that an even (or odd) number of bits are set to 1 in the transmitted bit string of N+r bits. The receiver can easily recompute the parity of each received bit string and discard the strings with an invalid parity. The parity scheme is often used when 7-bit characters are exchanged. In this case, the eighth bit is often a parity bit. The table below shows the parity bits that are computed for bit strings containing three bits.
3 bits string
Odd parity
Even parity
000
1
0
001
0
1
010
0
1
100
0
1
111
0
1
110
1
0
101
1
0
011
1
0
Table 3-3: Parity bits for bit strings containing three bits.
The parity bit allows a receiver to detect transmission errors that have affected a single bit among the transmitted N+r bits. If there are two or more bits in error, the receiver may not necessarily be able to detect the transmission error. More powerful error detection schemes have been defined. The cyclical redundancy check (CRC) is widely used in data link layer protocols. An N-bits CRC can detect all transmission errors affecting a burst of less than N bits in the transmitted frame and all transmission errors that affect an odd number of bits. Additional details about CRCs may be found in [Williams1993].
Error Correction Codes
It is also possible to design a code that allows the receiver to correct transmission errors. The simplest error correction code is the triple modular redundancy (TMR). To transmit a bit set to 1 (or 0), the sender transmits 111 (or 000). When there are no transmission errors, the receiver can decode 111 as 1. If transmission errors have affected a single bit, the receiver performs majority voting as shown in the table below. This scheme allows the receiver to correct all transmission errors that affect a single bit.
Received bits
Decoded bit
000
0
001
0
010
0
100
0
111
1
110
1
101
1
011
1
Table 3-4: If transmission errors have affected a single bit, the receiver performs majority voting.
Other more powerful error correction codes have been proposed and are used in some applications. The Hamming Code is a clever combination of parity bits that provides error detection and correction capabilities.
Reliable protocols use error detection schemes, but none of the widely used reliable protocols rely on error correction schemes. To detect errors, a frame is usually divided into two parts :
a header that contains the fields used by the reliable protocol to ensure reliable delivery. The header contains a checksum or cyclical redundancy check (CRC) [Williams1993] that is used to detect transmission errors.
a payload that contains the user data
Some headers also include a length field, which indicates the total length of the frame or the length of the payload.
More on Cyclical Redundacy Checks (CRCs)
Most of the protocols in the TCP/IP protocol suite rely on the simple Internet checksum in order to verify that a received packet has not been affected by transmission errors. Despite its popularity and ease of implementation, the Internet checksum is not the only available checksum mechanism. Cyclical redundancy checks(CRCs) are very powerful error detection schemes that are used notably on disks, by many data link layer protocols and file formats such as zip or png. They can easily be implemented efficiently in hardware and have better error-detection capabilities than the Internet checksum [SGP98] . However, CRCs are sometimes considered to be too CPU-intensive for software implementations and other checksum mechanisms are preferred. The TCP/IP community chose the Internet checksum, and the OSI community chose the Fletcher checksum[Sklower89]. Today, there are efficient techniques to quickly compute CRCs in software [Feldmeier95].
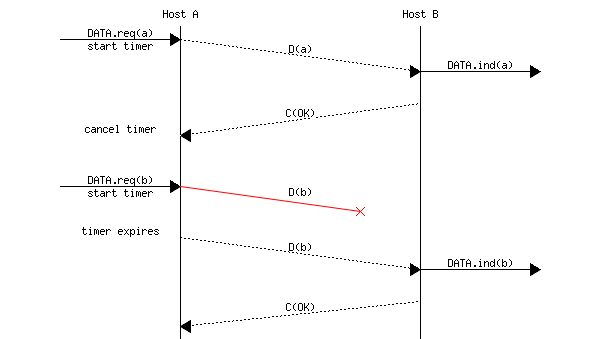
Since the receiver sends an acknowledgment after having received each data frame, the simplest solution to deal with losses is to use a retransmission timer. When the sender sends a frame, it starts a retransmission timer. The value of this retransmission timer should be larger than the round-trip-time, i.e., the delay between the transmission of a data frame and the reception of the corresponding acknowledgment. When the retransmission timer expires, the sender assumes that the data frame has been lost and retransmits it. This is illustrated in the figure below.
Figure 3-5: A retransmission of a frame after an expired time
Unfortunately, retransmission timers alone are not sufficient to recover from losses. Let us consider, as an example, the situation depicted below where an acknowledgment is lost. In this case, the sender retransmits the data frame that has not been acknowledged. However, as illustrated in the figure below, the receiver considers the retransmission as a new frame whose payload must be delivered to its user.
Figure 3-6: A retransmission of a frame as a new frame
This series of videos on Error Detection (2018-2019) by Ben Eater may be useful for diving deeper into these concepts!
Protocols Associated with the Data Link Layer
An important aspect of computer networks is the difference between a service and a protocol. Let’s use a real world example to illustrate. The traditional Post Office provides a service where a postal officer delivers letters to recipients. The Post Office precisely defines which types of letters (size, weight, etc.) can be delivered by using the Standard Mail service. Furthermore, the format of the envelope is specified (position of the sender and recipient addresses, position of the stamp). Someone who wants to send a letter must either place the letter at a Post Office or inside one of the dedicated mailboxes. The letter will then be collected and delivered to its final recipient. Note that for the regular service the Post Office usually does not guarantee the delivery of each particular letter. Some letters may be lost, and some letters are delivered to the wrong mailbox. If a letter is important, then the sender can use the registered service to ensure that the letter will be delivered to its recipient. Some Post Office services also provide an acknowledged service or an express mail service that is faster than the regular service. In the data link layer, HDLC (High-Level Data Link Control) functions like a modern courier service, supporting flexible peer-to-peer communication and delivery between any two points. Let’s learn about how HDLC evolved next.
SDLC: The Foundation of Synchronized Data Communication
In the history of data communications, the Synchronous Data Link Control (SDLC) protocol is a pioneer. Created by IBM during the 1970s, SDLC carved a path that would shape the way data moved between devices for decades to come. At its heart, SDLC is a bit-oriented, synchronous protocol, meaning that it exchanges data with a synchronized clock signal. This synchronization is essential for reliable communication between sender and receiver.
SDLC frames, the fundamental units of data exchange, bear a distinct structure. Each frame commences and concludes with a signature “flag sequence” (01111110 in binary), marking the frame’s start and end. Between these flags lies several fields: an address field identifying sender and receiver, a control field specifying frame type and control parameters, a variable-length data field, and a frame check sequence (FCS) field ensuring data integrity. Flow control mechanisms regulate data flow, preventing data overruns and loss. Acknowledgments and error detection via the FCS field add layers of reliability, guaranteeing successful frame transmission.
SDLC’s legacy extends beyond its own implementation, serving as the blueprint for the High-Level Data Link Control (HDLC) protocol and influencing many contemporary data link layer protocols. Although its prevalence has waned in modern networks, the principles and innovations that SDLC introduced remain vital to understanding the foundations of data communication and networking.
Asynchronous Communication Protocols
Asynchronous data communication protocols do not rely on strict clock synchronization, making them suitable in scenarios where real-time interaction is not required, or where flexibility, scalability, and fault tolerance are prioritized, such as modern distributed systems, event-driven applications, healthcare, collaboration tools, data streaming, and decentralized networks.
At its core, asynchronous communication relies on a start and stop bit mechanism, which provides a simple yet effective means to frame data for transmission. This start-stop framing allows data to be sent asynchronously, meaning that sender and receiver do not need to be precisely synchronized in time. Each character or byte of data is encapsulated with a start bit, followed by the data bits, optional parity bits for error checking, and one or more stop bits to signal the end of the character. This straightforward framing method enables data transmission without the need for a shared clock signal.
While asynchronous data communication is celebrated for its simplicity, it does come with trade-offs. Due to the start-stop framing overhead, it is less efficient than synchronous protocols when it comes to transmitting large volumes of data. Nonetheless, its adaptability and ease of implementation make it a vital part of the data link layer’s toolkit, bridging the gap between devices with simplicity. Next, let’s look at the history of PPP, a protocol that supports asynchronous and synchronous communications, and is still used in legacy systems, VPNs, IoT devices, and specialized networks.
The Point-to-Point Protocol
Many point-to-point datalink layers have been developed, starting in the 1960s. In this section, we focus on the protocols that are often used to transport IP packets between hosts or routers that are directly connected by a point-to-point link. This link can be a dedicated physical cable, a leased line through the telephone network or a dial-up connection with modems on the two communicating hosts.
The first solution to transport IP packets over a serial line was proposed in RFC 1055 and is known as Serial Line IP (SLIP). SLIP is a simple character stuffing technique applied to IP packets. SLIP defines two special characters : END(decimal 192) and ESC (decimal 219). END appears at the beginning and at the end of each transmitted IP packet and the sender adds ESC before each END character inside each transmitted IP packet. SLIP only supports the transmission of IP packets and it assumes that the two communicating hosts/routers have been manually configured with each other’s IP address. SLIP was mainly used over links offering bandwidth of often less than 20 Kbps. On such a low bandwidth link, sending 20 bytes of IP header followed by 20 bytes of TCP header for each TCP segment takes a lot of time. This initiated the development of a family of compression techniques to efficiently compress the TCP/IP headers. The first header compression technique proposed in RFC 1144 was designed to exploit the redundancy between several consecutive segments that belong to the same TCP connection. In all these segments, the IP addresses and port numbers are always the same. Furthermore, fields such as the sequence and acknowledgment numbers do not change in a random way. RFC 1144 defined simple techniques to reduce the redundancy found in successive segments. The development of header compression techniques continued and there are still improvements being developed now RFC 5795.
While SLIP was implemented and used in some environments, it had several limitations discussed in RFC 1055. The Point-to-Point Protocol (PPP) was designed shortly after and is specified in RFC 1548. PPP aims to support IP and other network layer protocols over various types of serial lines. PPP is, in fact, a family of three protocols that are used together :
The Point-to-Point Protocol defines the framing technique to transport network layer packets.
The Link Control Protocol is used to negotiate options and authenticate the session by using username and password or other types of credentials.
The Network Control Protocol is used to negotiate options that are specific for each protocol. For example, IPv4’s NCP RFC 1548 can negotiate the IPv4 address to be used, the IPv4 address of the DNS resolver. IPv6’s NCP is defined in RFC 5072.
The PPP framing RFC 1662 was inspired by the data link layer protocols standardized by ITU-T and ISO. A typical PPP frame is composed of the fields shown in the figure below. A PPP frame starts with a one-byte flag containing 01111110. PPP can use bit stuffing or character stuffing depending on the environment where the protocol is used. The address and control fields are present for backward compatibility reasons. The 16-bit protocol field contains the identifier of the network layer protocol that is carried in the PPP frame. 0x002d is used for an IPv4 packet compressed with RFC 1144 while 0x002f is used for an uncompressed IPv4 packet. 0xc021 is used by the Link Control Protocol, 0xc023 is used by the Password Authentication Protocol (PAP). 0x0057 is used for IPv6 packets. PPP supports variable-length packets, but LCP can negotiate a maximum packet length. The PPP frame ends with a frame check sequence. The default is a 16 bits CRC, but some implementations can negotiate a 32 bits CRC. The frame ends with the 01111110 flag.
Figure 3-7: PPP frame format
PPP played a key role in allowing Internet Service Providers (ISPs) to provide dial-up access over modems in the late 1990s and early 2000s. ISPs operated modem banks connected to the telephone network. For these ISPs, a key issue was to authenticate each user connected through the telephone network. This authentication was performed by using the Extensible Authentication Protocol (EAP) defined in RFC 3748. EAP is a simple, but extensible protocol that was initially used by access routers to authenticate the users connected through dial-up lines. Several authentication methods, starting from the simple username/password pairs to more complex schemes have been defined and implemented. When ISPs started to upgrade their physical infrastructure to provide Internet access over Asymmetric Digital Subscriber Lines (ADSL), they attempted to reuse their existing authentication (and billing) systems. To meet these requirements, the IETF developed specifications to allow PPP frames to be transported over other networks than the point-to-point links for which PPP was designed. Nowadays, most ADSL deployments use PPP over either ATM RFC 2364 or Ethernet RFC 2516. The IANA maintains the registry of all assigned PPP protocol fields at http://www.iana.org/assignments/ppp-numbers.
We will reference numerous RFCs (Request for Comments) in this text. RFCs trace their origins to the early days of the ARPANET, the precursor to today’s internet. As researchers and engineers collaborated to build this groundbreaking network, they needed a way to document the evolving protocols and standards. Hence, RFCs were born. They became a means to share ideas, propose standards, and provide detailed technical specifications for various aspects of data communication, from internet protocols (like TCP/IP and HTTP) to email standards (like SMTP).
Why do we think of RFCs as “living documents”?
How do RFCs contribute to the standardization of telecommunications and networking functions?
How are RFCs used by data communication professionals and engineers in practice?
The ARP Protocol
The Address Resolution Protocol (ARP) is a fundamental protocol in computer networking that operates at the data link layer of the OSI model. Its primary function is to find the physical MAC address associated with a given IP address. When a device needs to send data to another device on the same network, it must know the destination’s MAC address to encapsulate the data into an Ethernet frame. ARP bridges this gap by resolving the MAC address to its IP address, ensuring that data packets reach their intended destination. This process is essential for local network communication, as MAC addresses are required for data transmission at the physical level.
Since this protocol functions at the Ethernet segment level, security was not a primary concern. Unfortunately, this means that ARP communications can be easily spoofed to cause a man-in-the-middle (MitM) scenario. A malicious actor simply sends out several ARP packets, gratuitous arp, saying that traffic for a certain IP address should be sent to them. Since the MAC to IP address table is cached in several places, it can take a long time for all the caches to invalidate and resolve an issue caused by malicious ARP frames.
There is a protocol designed to mitigate the issues with ARP. Dynamic ARP Inspection (DAI) reaches across layers to work with the DHCP lease database and drop packets that are not using the MAC address used when a DHCP lease was granted. While this can solve many of the issues associated with ARP, it is also a good practice to use secure higher-level protocols such as HTTPS as an additional measure.
We will discuss how to get IP datagrams to the right physical network later, but how do we get a datagram to a particular host or router on that network? The main issue is that IP datagrams contain IP addresses, but the physical interface hardware on the host or router to which you want to send the datagram only understands the addressing scheme of that particular network. Thus, we need to translate the IP address to a link-level address that makes sense on this network (e.g., a 48-bit Ethernet address). We can then encapsulate the IP datagram inside a frame that contains that link-level MAC address and send it either to the ultimate destination or to a router that promises to forward the datagram toward the ultimate destination.
One simple way to map an IP address into a physical network address is to encode a host’s physical address in the host part of its IP address. For example, a host with physical address 0010000101010001 (which has the decimal value 33 in the upper byte and 81 in the lower byte) might be given the IP address 128.96.33.81. While this solution has been used on some networks, it is limited in that the network’s physical addresses can be no more than 16 bits long in this example; they can be only 8 bits long on a class C network. This clearly will not work for 48-bit Ethernet addresses.
A more general solution would be for each host to maintain a table of address pairs; that is, the table would map IP addresses into physical addresses. While this table could be centrally managed by a system administrator and then copied to each host on the network, a better approach would be for each host to dynamically learn the contents of the table using the network. This can be accomplished using the Address Resolution Protocol (ARP). The goal of ARP is to enable each host on a network to build up a table of mappings between IP addresses and link-level addresses. Since these mappings may change over time (e.g., because an Ethernet card in a host breaks and is replaced by a new one with a new address), the entries are timed out periodically and removed. This happens on the order of every 15 minutes. The set of mappings currently stored in a host is known as the ARP cache or ARP table.
ARP takes advantage of the fact that many link-level network technologies, such as Ethernet, support broadcast. If a host wants to send an IP datagram to a host (or router) that it knows to be on the same network (i.e., the sending and receiving nodes have the same IP network number), it first checks for a mapping in the cache. If no mapping is found, it invokes the Address Resolution Protocol over the network. It does this by broadcasting an ARP query onto the network. This query contains the IP address in question (the target IP address). Each host receives the query and checks to see if it matches its IP address. If it does match, the host sends a response message that contains its link-layer address back to the originator of the query. The originator adds the information contained in this response to its ARP table. The query message also includes the IP address and link-layer address of the sending host.
Thus, when a host broadcasts a query message, each host on the network can learn the sender’s link-level and IP addresses and place that information in its ARP table. However, not every host adds this information to its ARP table. If the host already has an entry for that host in its table, it “refreshes” this entry; that is, it resets the length of time until it discards the entry. If that host is the target of the query, then it adds the information about the sender to its table, even if it did not already have an entry for that host. This is because there is a good chance that the source host is about to send it an application-level message, and it may eventually have to send a response or acknowledgment back to the source; it will need the source’s physical address to do this. If a host is not the target and does not already have an entry for the source in its ARP table, then it does not add an entry for the source. This is because there is no reason to believe that this host will ever need the source’s link-level address; there is no need to clutter its ARP table with this information.
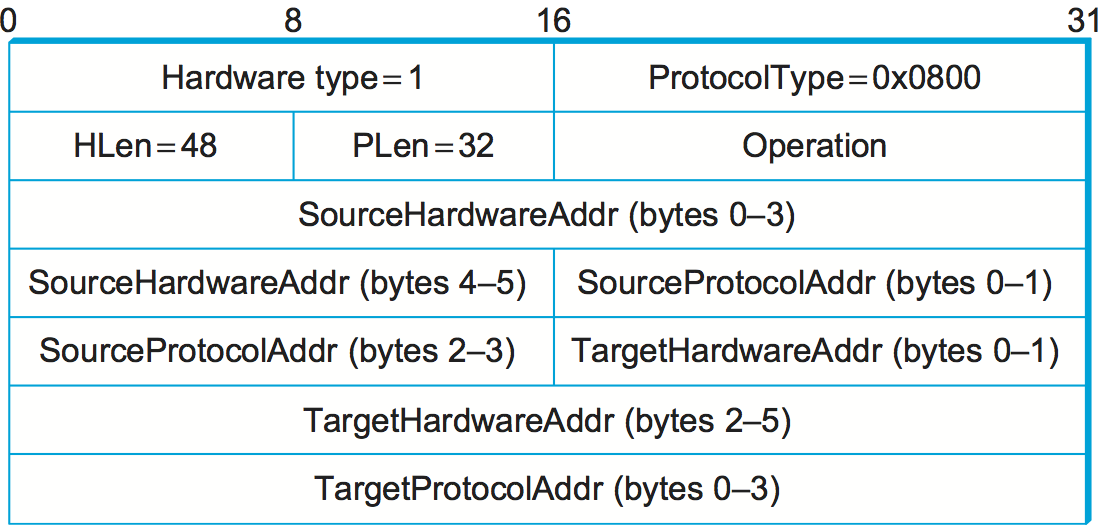
Figure 3-8: ARP packet format for mapping IP addresses into Ethernet addresses.
The figure above shows the ARP packet format for IP-to-Ethernet address mappings. In fact, ARP can be used for lots of other kinds of mappings—the major differences are in the address sizes. In addition to the IP and link-layer addresses of both sender and target, the packet contains the following:
A HardwareType field, which specifies the type of physical network (e.g., Ethernet)
A ProtocolType field, which specifies the higher-layer protocol (e.g., IP)
HLen (“hardware” address length) and PLen (“protocol” address length) fields, which specify the length of the link-layer address and higher-layer protocol address, respectively
An Operation field, which specifies whether this is a request or a response
The source and target hardware (MAC) address and protocol (IP) addresses
[30] J. Stone, M. Greenwald, C. Partridge, and J. Hughes, “Performance of checksums and CRCs over real data,” IEEE/ACM Transactions on Networking, vol. 6, no. 5, pp. 529–543, Oct. 1998, doi: 10.1109/90.731187. Available: https://ieeexplore.ieee.org/document/731187/
[31] K. Sklower, “Improving the efficiency of the OSI checksum calculation,” SIGCOMM Comput. Commun. Rev., vol. 19, no. 5, pp. 32–43, Oct. 1989, doi: 10.1145/74681.74684. Available: https://dl.acm.org/doi/10.1145/74681.74684
[32] D. C. Feldmeier, “Fast software implementation of error detection codes,” IEEE/ACM Transactions on Networking, vol. 3, no. 6, pp. 640–651, Dec. 1995, doi: 10.1109/90.477710. Available: https://ieeexplore.ieee.org/document/477710
Do you have any comments (errors, suggestions, etc.) about this section? Please ping us by clicking on the link below and sharing your feedback/suggestions. Thank you!